Context-Aware RL for Agentic and Multimodal LLMs

†Equal advising contribution
Modern LLMs must ground decisions in sparse yet decisive contextual evidence — an early observation in a long agent trajectory, a single tool-trace line, or a subtle visual detail. When such evidence is overlooked, models produce locally plausible but context-inconsistent outputs. We call this failure mode context unawareness.
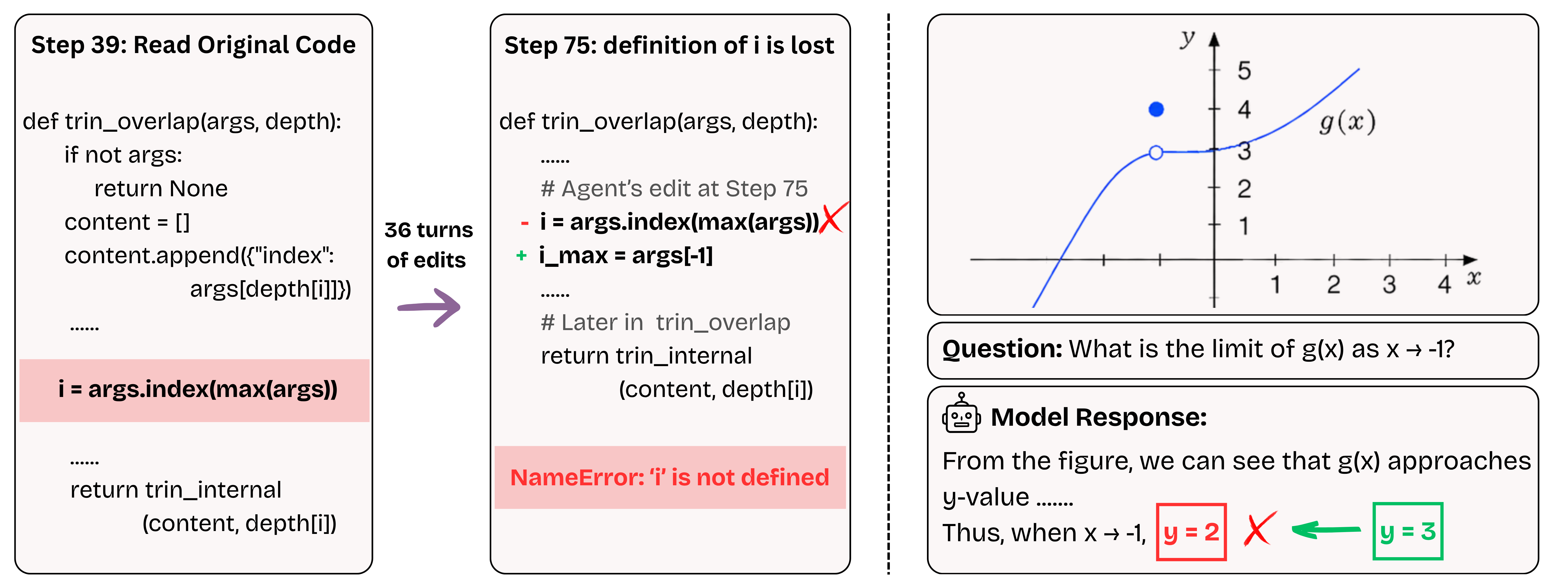
Figure 1: Context unawareness in agentic and multimodal settings.
Left: The model removes the definition of i that is later referenced,
causing a runtime error.
Right: The model misreads \(g(x) \to y\!=\!3\) as \(2\), producing an incorrect answer.
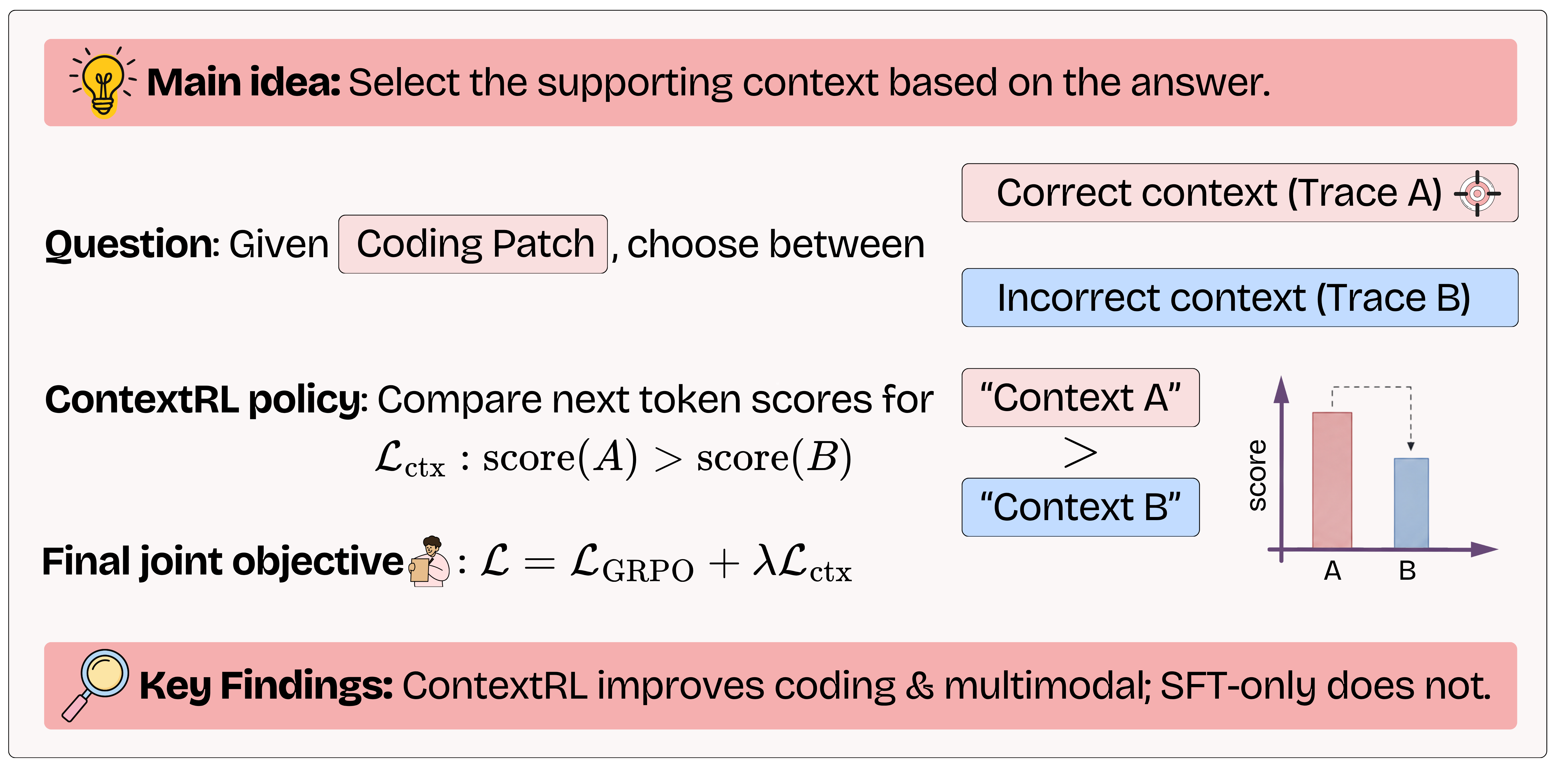
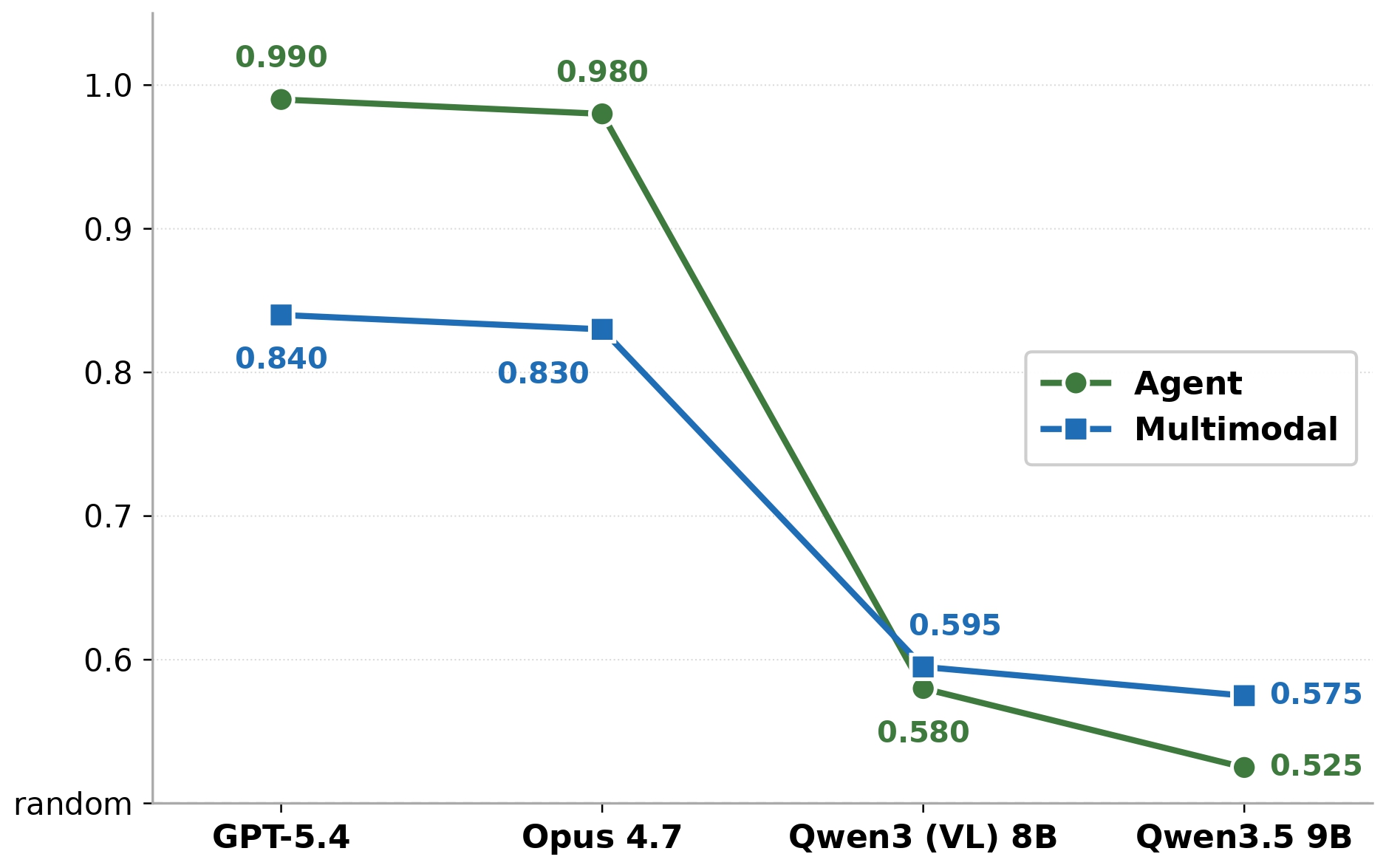
A controlled contrastive context probe reveals a ~40-point gap between proprietary and open-source models on context-selection accuracy, despite open-source models being competitive on standard benchmarks. Motivated by this, we propose ContextRL, a post-training method that augments GRPO with a logit-level contrastive loss over 1k agentic and 7k multimodal contrastive context pairs.
To quantify context unawareness, we construct a controlled contrastive context probe: 200 contrastive pairs from agentic trajectories and 200 from visual question answering (VQA) images. Each example presents the model with a question, a candidate answer, and two closely matched contexts that support different answers — the model must select the context that justifies the candidate answer.
This simple test reveals a ~40-point gap between proprietary models (GPT-4.1, Claude Opus 4.7) and widely-used open-source models. Notably, strong open-source models such as Qwen3-VL 8B and Qwen3.5 9B perform near random choice on this probe, despite their competitive performance on standard benchmarks. These results suggest that strong benchmark performance can obscure failures in context grounding.
Pairs are designed to be surface-similar but differ in one semantically decisive region, forcing genuine context understanding rather than exploitation of surface statistics.
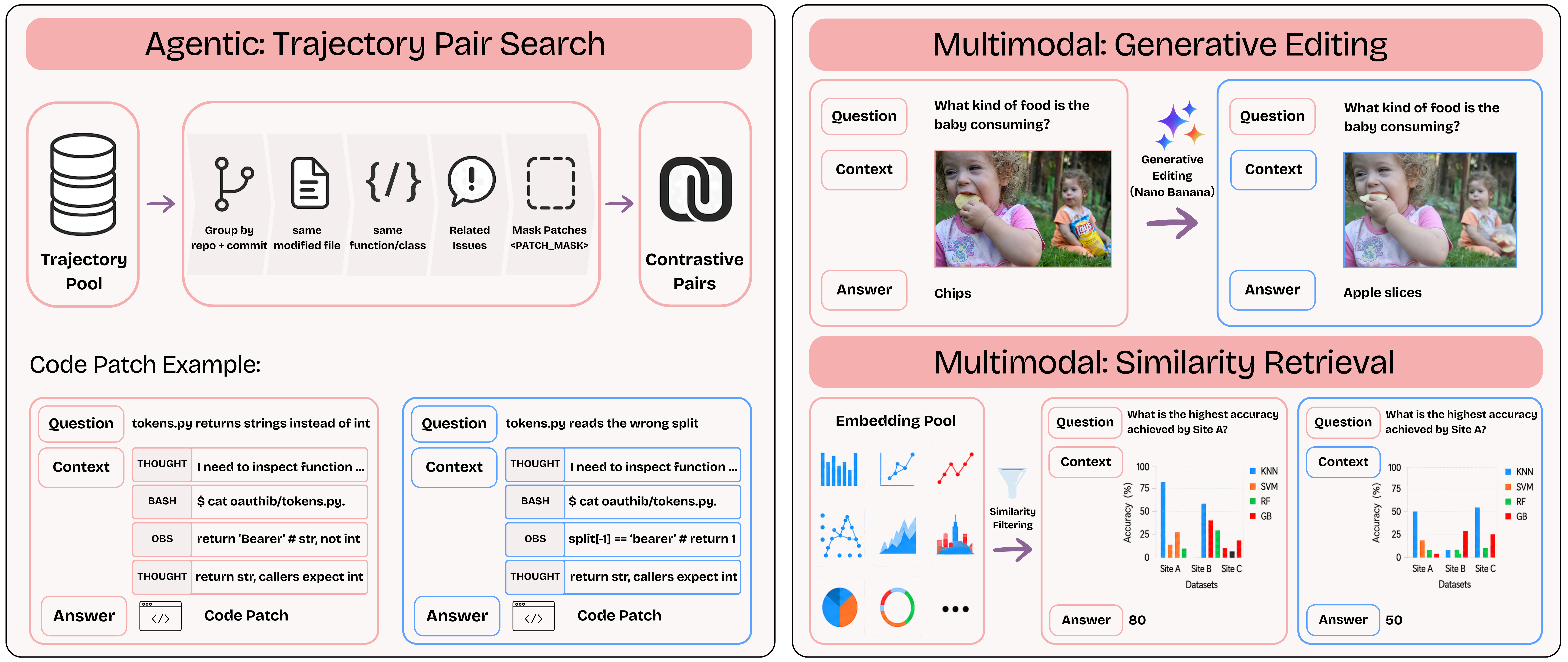
Figure 4: Contrastive context pairs construction pipeline. Left: Step-by-step filtering to mine contrastive trajectory pairs for the agentic setting. Right: Generative editing and similarity-based retrieval to mine contrastive image pairs for the multimodal setting. A concrete \((C^+, C^-)\) example is shown alongside each method.
Agentic: Trajectory Pair Search
From 66k SWE-smith trajectories, a cascade of four filters (same repo/commit → same file → same function → related issues) extracts 1k high-quality pairs. Patch contents are masked; GPT-5 rejects shortcut cues and ambiguous labels.
Multimodal: Image Pair Mining
Covers five visual domains. Two strategies: Generative editing: GPT-5 instructs Nano Banana 2 to alter natural images; yields ~700 pairs from 2k candidates. Similarity-based retrieval: high-cosine but different-answer image pairs via Qwen3-VL-Embedding-8B; yields 6,300 pairs from 200k candidates.
Context-Aware Reinforcement Learning (ContextRL) augments standard GRPO with an explicit context-selection signal: alongside the task reward, the model is trained to identify which context supports a given answer. Each contrastive instance \(z = (Q, A, C^+, C^-)\) pairs an anchor answer \(A\) with a supporting context \(C^+\) and a minimally perturbed confounding alternative \(C^-\) — a trajectory for agentic coding, an image for multimodal tasks.
The model is asked to select between \(C^+\) and \(C^-\) as a two-way choice. Let \(\Delta_\theta(z) = \ell_\theta^+(z) - \ell_\theta^-(z)\) be the logit margin between the two option tokens (computed by teacher forcing). We optimize:
$$\mathcal{L}_{\mathrm{CA}}(z;\,\theta)\;=\;-\log\,\sigma\!\left(\mathrm{clip}\!\left(\Delta_\theta(z),\;-c,\;c\right)\right)$$
\(\sigma\) is the sigmoid; \(c > 0\) clips the margin to prevent large gradients from dominating training. The loss is modality-agnostic — identical for trajectories and images.
The final objective mixes the task RL signal with the context-awareness loss:
$$\mathcal{L}(\theta)\;=\;\mathbb{E}_{x\,\sim\,\mathcal{D}_{\mathrm{RL}}}\!\left[\mathcal{L}_{\mathrm{GRPO}}(x;\theta)\right] \;+\;\lambda\;\mathbb{E}_{z\,\sim\,\mathcal{D}_{\mathrm{CA}}}\!\left[\mathcal{L}_{\mathrm{CA}}(z;\theta)\right]$$
\(\mathcal{L}_{\mathrm{GRPO}}\) rewards correct outputs; \(\mathcal{L}_{\mathrm{CA}}\) enforces context grounding. \(\lambda\) balances the two. The same formulation applies to both agentic and multimodal settings.
Trained on 8k instances (7k SWE-Gym + 1k contrastive pairs) from two base models: Qwen3-8B and Klear-AgentForge-8B. Evaluated on 2 in-distribution (SWE-Bench) and 3 out-of-distribution benchmarks (LiveCodeBench, LongBench v2, NIAH).
| Model | In-distribution | Out-of-distribution | ||||
|---|---|---|---|---|---|---|
| SWE-Bench Verified |
SWE-Bench Lite |
LiveCodeBench v6 |
LongBench v2 Overall |
LongBench v2 Long |
NIAH | |
| Off-the-shelf reference models | ||||||
| Qwen3-14B | 8.40 | 6.00 | 57.1 | 34.2 | 24.1 | 99.5 |
| Qwen3-32B | 8.40 | 6.00 | 61.1 | 36.8 | 31.5 | 99.3 |
| Qwen3-Coder-30B | 28.8 | 22.0 | 37.7 | 42.5 | 41.7 | 85.7 |
| Trained from Qwen3-8B | ||||||
| Base model | 5.00 | 2.70 | 44.6 | 31.6 | 27.8 | 98.8 |
| RL baseline (GRPO) | 6.20 | 2.70 | 46.3 | 31.8 | 26.9 | 98.5 |
| ContextRL (Ours) | 7.00 | 4.00 | 47.4 | 33.2 | 29.6 | 99.0 |
| Trained from Klear-AgentForge-8B | ||||||
| Base model | 26.6 | 21.0 | 21.7 | 27.4 | 21.3 | 68.3 |
| RL baseline (GRPO) | 28.0 | 21.7 | 22.3 | 27.0 | 24.1 | 65.5 |
| ContextRL (Ours) | 30.2 | 24.0 | 24.0 | 29.6 | 28.7 | 71.3 |
Table 1: Main results on long-horizon benchmarks. ContextRL consistently outperforms the RL baseline across all tasks for both base models. Resolve rate (%) is reported for SWE-Bench; accuracy (%) for others.
Trained on 45k instances (38k standard QA + 7k contrastive pairs) on Qwen2.5-VL-7B and Qwen3-VL-8B. Compared against GRPO and PAPO (a recent perception-aware RL baseline).
| Benchmark | Qwen2.5-VL-7B | Qwen3-VL-8B | |||||
|---|---|---|---|---|---|---|---|
| Base | RL Base | PAPO | Ours | Base | RL Base | Ours | |
| Mathematical Reasoning | |||||||
| MathVista | 68.2 | 72.5 | 72.7 | 73.6 | 75.8 | 78.7 | 79.8 |
| MathVerse | 43.9 | 45.3 | 49.7 | 49.1 | 56.1 | 65.0 | 66.4 |
| MathVision | 22.8 | 25.5 | 27.3 | 26.8 | 46.2 | 49.2 | 52.0 |
| General Multimodal Understanding | |||||||
| MMMU-Pro | 36.6 | 41.3 | 42.6 | 42.8 | 41.3 | 55.9 | 57.5 |
| MMMU | 50.7 | 53.3 | 53.2 | 54.6 | 66.4 | 69.1 | 70.1 |
| Fine-grained Visual Perception | |||||||
| V* | 70.1 | 70.7 | 71.7 | 73.3 | 82.2 | 84.8 | 85.9 |
| MMStar | 62.6 | 64.1 | 63.4 | 65.1 | 70.5 | 73.5 | 74.8 |
| BLINK | 55.3 | 56.5 | 58.5 | 58.9 | 64.4 | 65.1 | 66.6 |
| Scientific Reasoning | |||||||
| ScienceQA | 88.2 | 91.0 | 92.7 | 95.4 | 94.4 | 95.6 | 96.6 |
| PhyX | 25.4 | 48.7 | 46.8 | 50.0 | 45.5 | 72.1 | 73.4 |
| OlympiadBench Phy | 1.5 | 3.1 | 2.2 | 4.6 | 7.9 | 8.1 | 9.9 |
| Real-world Scene Understanding | |||||||
| MME-RealWorld Lite | 38.4 | 45.1 | 45.1 | 46.7 | 48.7 | 51.9 | 54.8 |
| Overall Avg. | 47.0 | 51.4 | 52.2 | 53.4 | 58.3 | 64.1 | 65.7 |
Table 2: Main results on 12 diverse multimodal benchmarks. ContextRL achieves the best performance across all sub-categories and surpasses both the RL baseline and the strong reference method PAPO. Accuracy (%) is reported.
We ablate whether the gain comes from the contrastive data or the objective, comparing against DA-SFT (SFT on contrastive data then GRPO) and DA-RL (contrastive data as binary 0/1 RL reward).
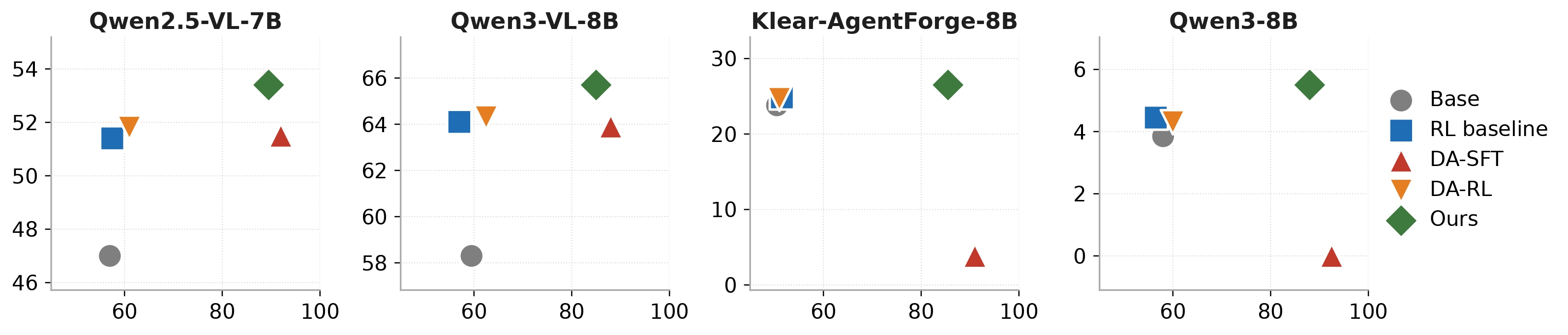
Figure 5: Context-selection accuracy versus end-task performance. The \(x\)-axis denotes selection accuracy and the \(y\)-axis denotes end-task performance. Top-right is optimal. DA-SFT achieves high selection accuracy but collapses on the \(y\)-axis. DA-RL fails to learn discrimination at all. ContextRL is the only method that couples high context awareness with consistent end-task improvements across all four model configurations.
Two design choices keep ContextRL from both failure modes:
(a) Updates Remain Constrained
GRPO's importance-ratio clipping and KL regularization keep the policy near \(\pi_\mathrm{ref}\), while the clipped margin suppresses auxiliary gradients once \(C^+\) and \(C^-\) are well separated, preventing the catastrophic forgetting seen in DA-SFT.
(b) The Auxiliary Signal is Dense
Unlike DA-RL's sparse 0/1 rewards, \(\mathcal{L}_{\mathrm{CA}}\) provides dense gradient signal on every contrastive example, even when the policy rarely samples the correct context.
TODO: Add BibTeX