|
Peiyang Xu I'm a first-year Ph.D. student in Electrical and Computer Engineering at Princeton University. I earned my Bachelor's degree from Tsinghua University, majoring in Computer Science and Technology. Previously, I was fortunate to have worked as a research intern at University of Chicago under the supervision of Professor Bo Li. I also had the honor of being advised by Professor Xiaolin Hu at Tsinghua University. Email / CV / Google Scholar |

|
ResearchI'm deeply interested in Trustworthy Machine Learning, Adversarial Machine Learning, and the use of Multimodal Large Language Models. Questions like “How can we make AI more reliable?” (e.g., adversarial attacks, hallucination in MLLMs) and “How can we fully harness AI for the benefit of humanity?” (e.g., guardrail models) are at the heart of my research pursuits, and I am committed to exploring these issues through my graduate studies. |
|
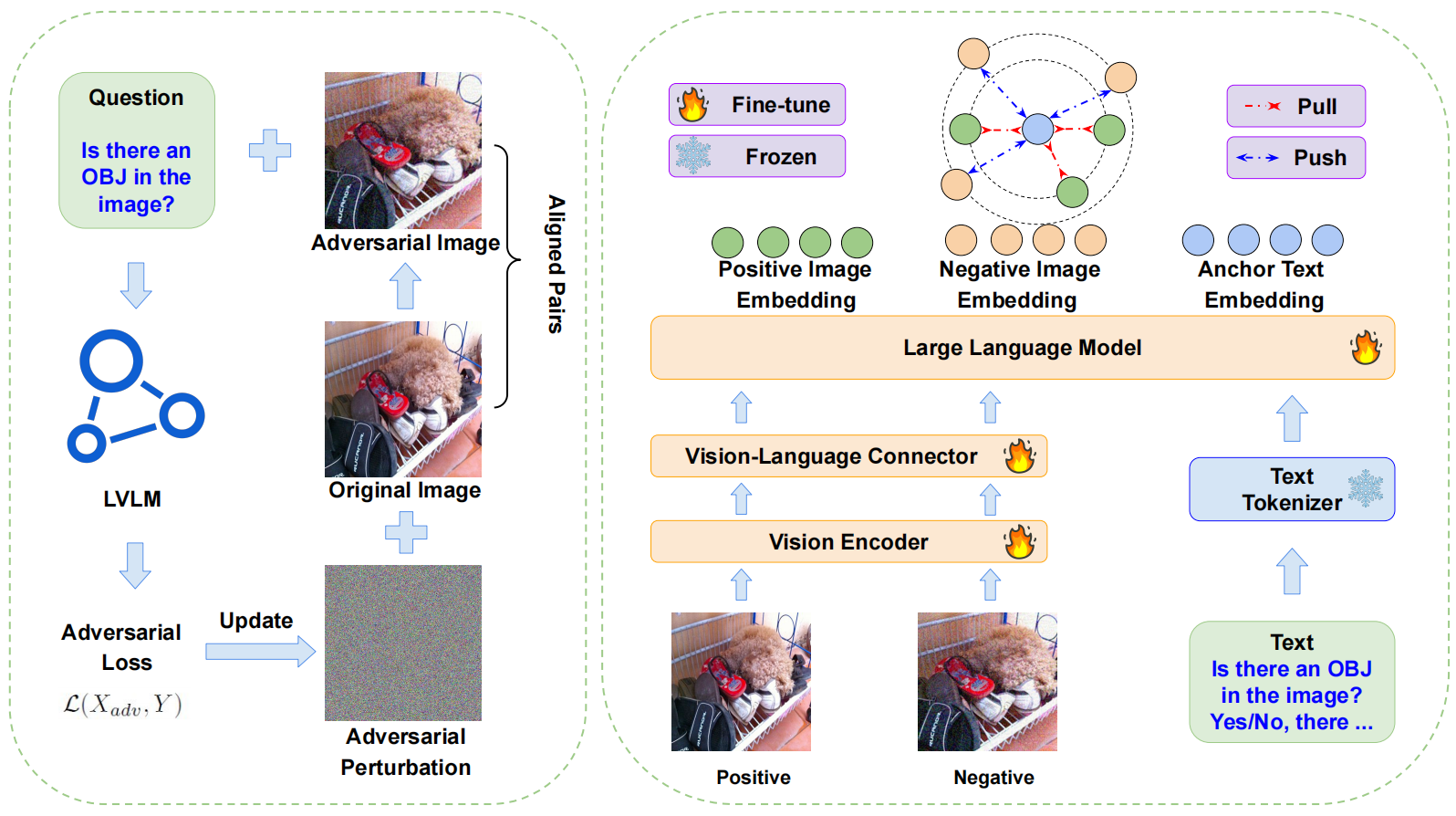
We propose Adversarial Contrastive Finetuning (ACFT), a novel method to mitigate object hallucination in LVLMs. |
|
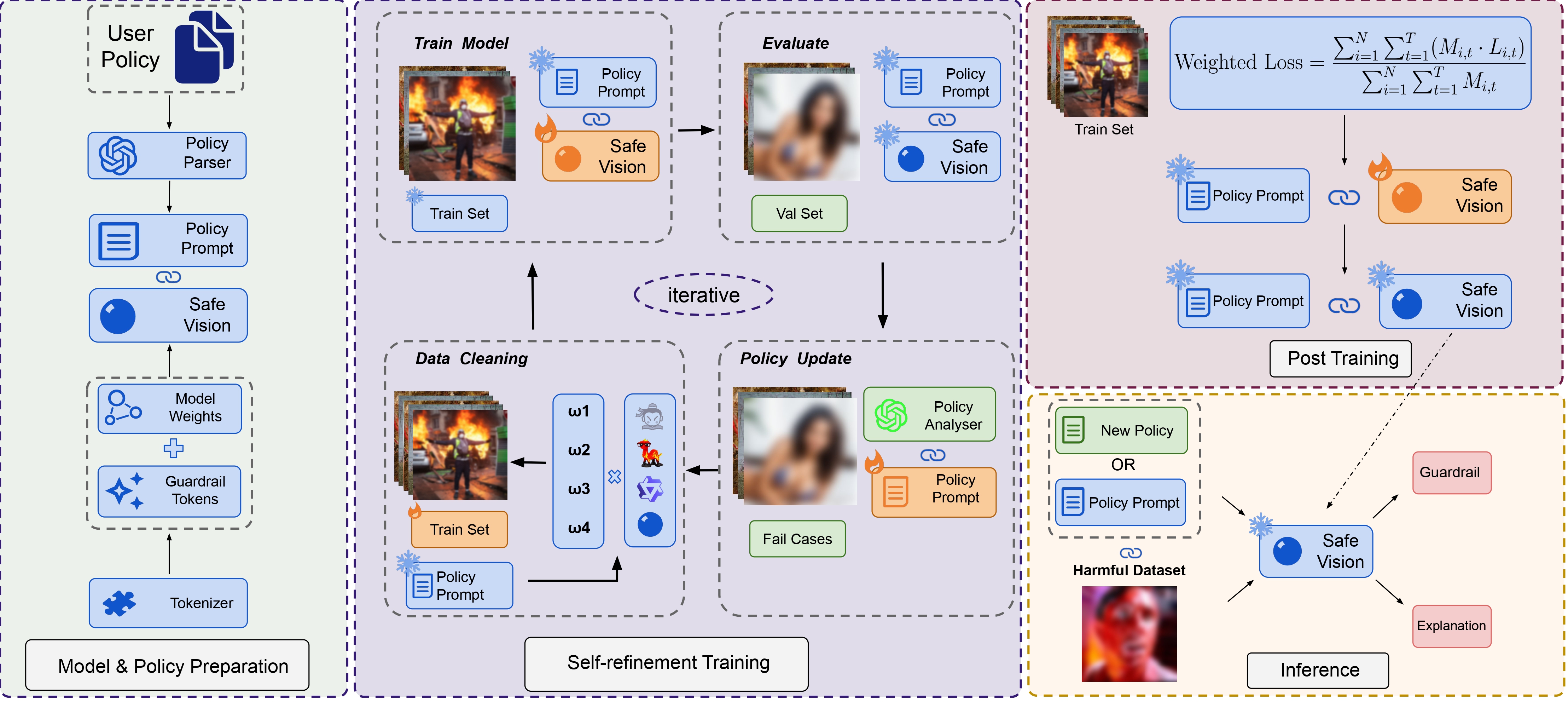
We propose SafeVision, a novel image guardrail system that integrates human-like understanding and reasoning. |

|
We present the first unified platform, MMDT, designed to provide a comprehensive safety and trustworthiness evaluation for multimodal foundation models. |

|
We propose a natural language induced adversarial attack method. The core idea is to leverage a text-to-image model to generate adversarial images given maliciously constructed prompts. |
|
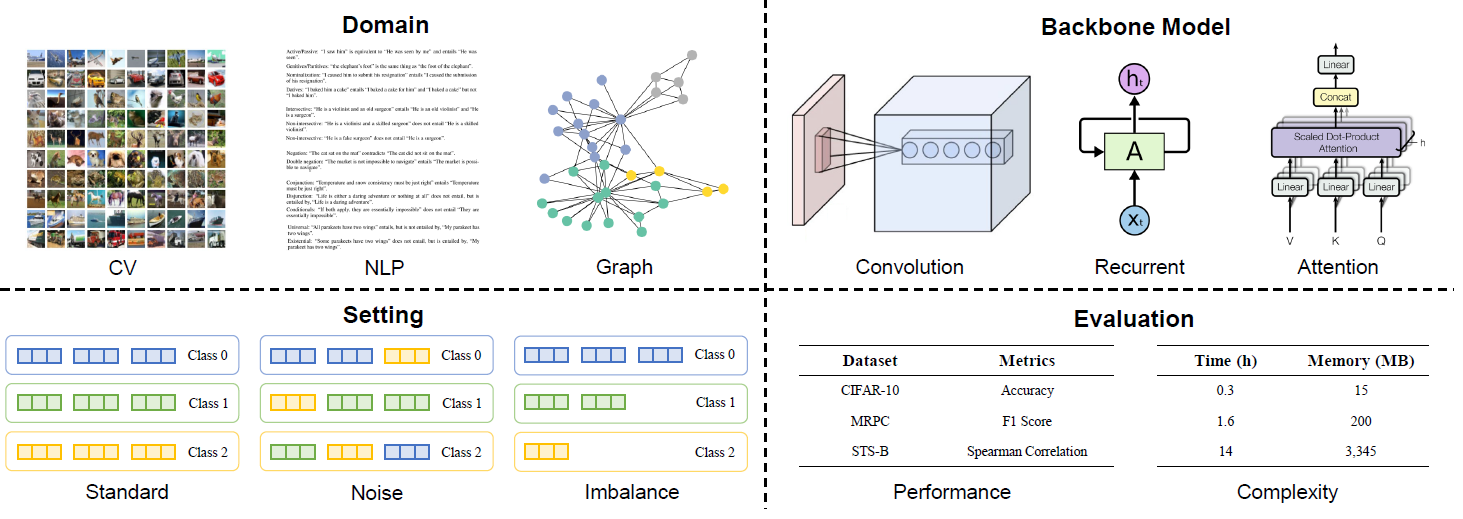
We develop CurBench, the first benchmark that supports systematic evaluations for curriculum learning consisting of 3 research domains. |
|
Website template from here. |